Hi Bekarys,
Feel free to join our discord server <https://discord.gg/EgerE5nzvk> for
more information and discussions on GovDoc Scanner. We have also
created a Frequently
Asked Questions <https://github.com/flexivian/govdoc-scanner/discussions/1> in
the Github repository discussions section. You can find most asked
questions there.
Regarding your question, robots.txt on https://publicity.businessportal.gr/
stops us from crawling on this website, so you can update/modify your
proposals assuming that the crawler is out of scope. Alternatively, we can
provide you with some specific PDFs, e.g. from 20 companies, downloaded
directly from GEMI portal, and we can store them in our own storage server
to be used by the scanner tool.
In order to find a PDF for a company you can follow those steps:
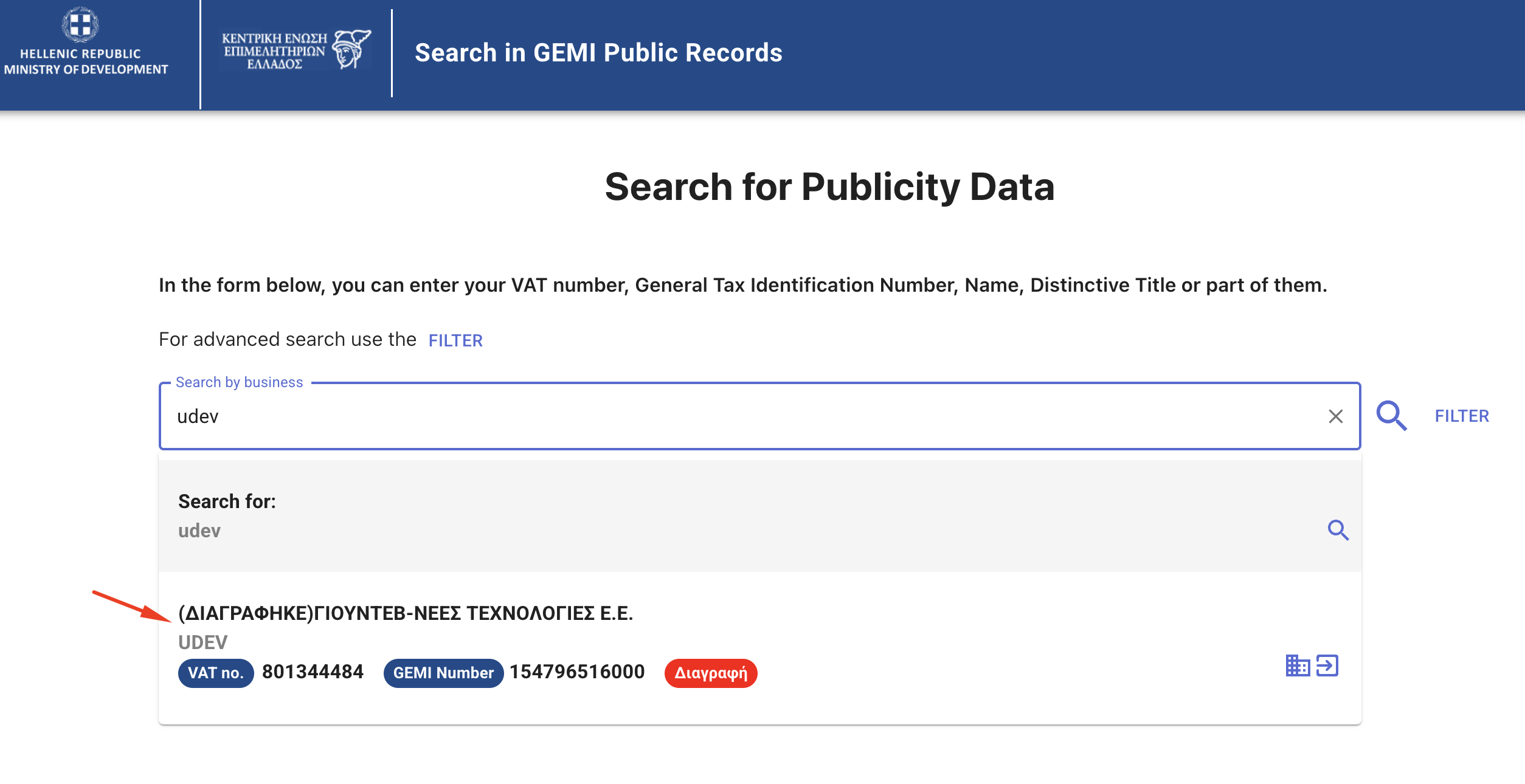
1. Navigate to https://publicity.businessportal.gr/
2. Enter 'udev' in the search bar and select the company
[image: image.png]
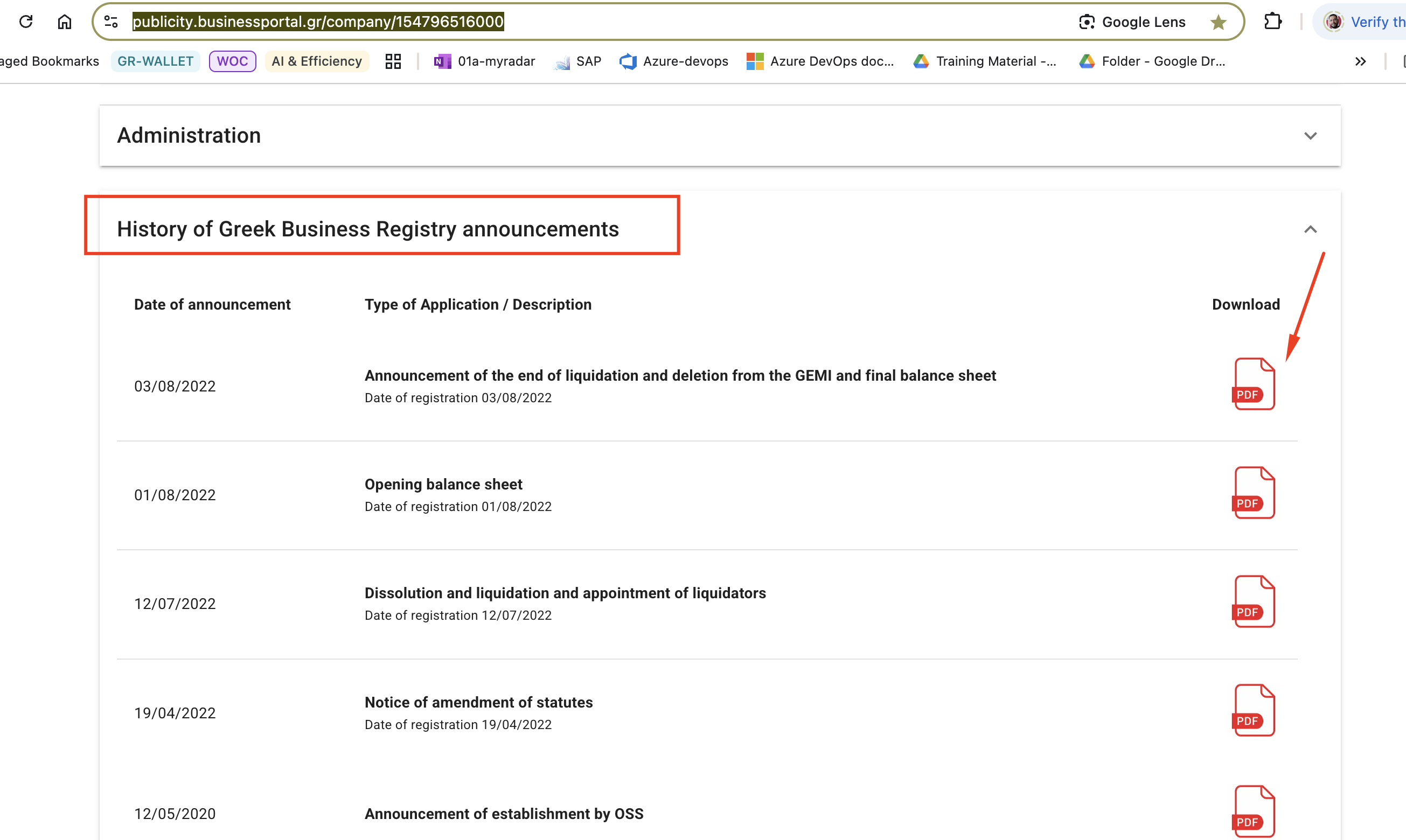
3. Select "History of Greek Business Registry announcements" ("Ιστορικό
ανακοινώσεων Γ.Ε.ΜΗ." in Greek) to find related PDFs
[image: image.png]
4. Download the PDF 'Announcement of establishment by OSS'
[image: image.png]
The goal is to be able to parse specific data from PDFs (expecting various
templates to be used by the lawyers of each company) and extract
information for legal representatives, eg. I was representing UDEV, and
this info can be found under section 6
[image: image.png]
So the challenge here is the language, various doc templates, the specific
info we want to extract from files which probably have been exported to
PDFs in various ways, and on top of that to keep version history of the
extracted data.
Regards,
Giannis
--
Ioannis Skitsas
On Thu, Apr 3, 2025 at 5:22 PM Бекарыс Сериков <bekaryss03 [ at ] gmail [ dot ] com> wrote:
> Hello, I’m Bekarys Serikov, a third-year student at Nazarbayev University,
> and I’m excited about contributing to the "Flexible GovDoc Scanner" project
> for GSoC 2025. I’ve been exploring the ΓΕΜΗ portal (
> publicity.businessportal.gr) to understand the crawling task, which
> mentions gathering "PDF documents." However, when I search the site, I
> mostly see web-based results rather than PDFs. Could someone clarify where
> these PDF documents are located or how they’re accessed on the portal? I’d
> really appreciate any guidance!
>
> Sincerely,
> Bekarys Serikov
> ----
> Λαμβάνετε αυτό το μήνυμα απο την λίστα: Λίστα αλληλογραφίας και συζητήσεων
> που απευθύνεται σε φοιτητές developers \& mentors έργων του Google Summer
> of Code - A discussion list for student developers and mentors of Google
> Summer of Code projects.,
> https://lists.ellak.gr/gsoc-developers/listinfo.html
> Μπορείτε να απεγγραφείτε από τη λίστα στέλνοντας κενό μήνυμα ηλ.
> ταχυδρομείου στη διεύθυνση <gsoc-developers+unsubscribe [ at ] ellak [ dot ] gr>.
>


----
Λαμβάνετε αυτό το μήνυμα απο την λίστα: Λίστα αλληλογραφίας και συζητήσεων που απευθύνεται σε φοιτητές developers \& mentors έργων του Google Summer of Code - A discussion list for student developers and mentors of Google Summer of Code projects.,
https://lists.ellak.gr/gsoc-developers/listinfo.html
Μπορείτε να απεγγραφείτε από τη λίστα στέλνοντας κενό μήνυμα ηλ. ταχυδρομείου στη διεύθυνση <gsoc-developers+unsubscribe [ at ] ellak [ dot ] gr>.