Hi Iordanis,
Feel free to join our discord server <https://discord.gg/EgerE5nzvk> for
more information and discussions on GovDoc Scanner. We have also
created a Frequently
Asked Questions <https://github.com/flexivian/govdoc-scanner/discussions/1> in
the Github repository discussions section. You can find most asked
questions there.
Regarding opendata (https://opendata.businessportal.gr/) offered through
REST APIs, we can request an API key (register
<http://opendata.businessportal.gr/register/> page is not working though
-404-not-found, I will try to reach them) and utilize the service where
needed. However the goal is to automate a workflow where we extract and
identify data from PDFs utilizing various AI and other techniques.
In order to find a PDF for a company you can follow those steps:
1. Navigate to https://publicity.businessportal.gr/
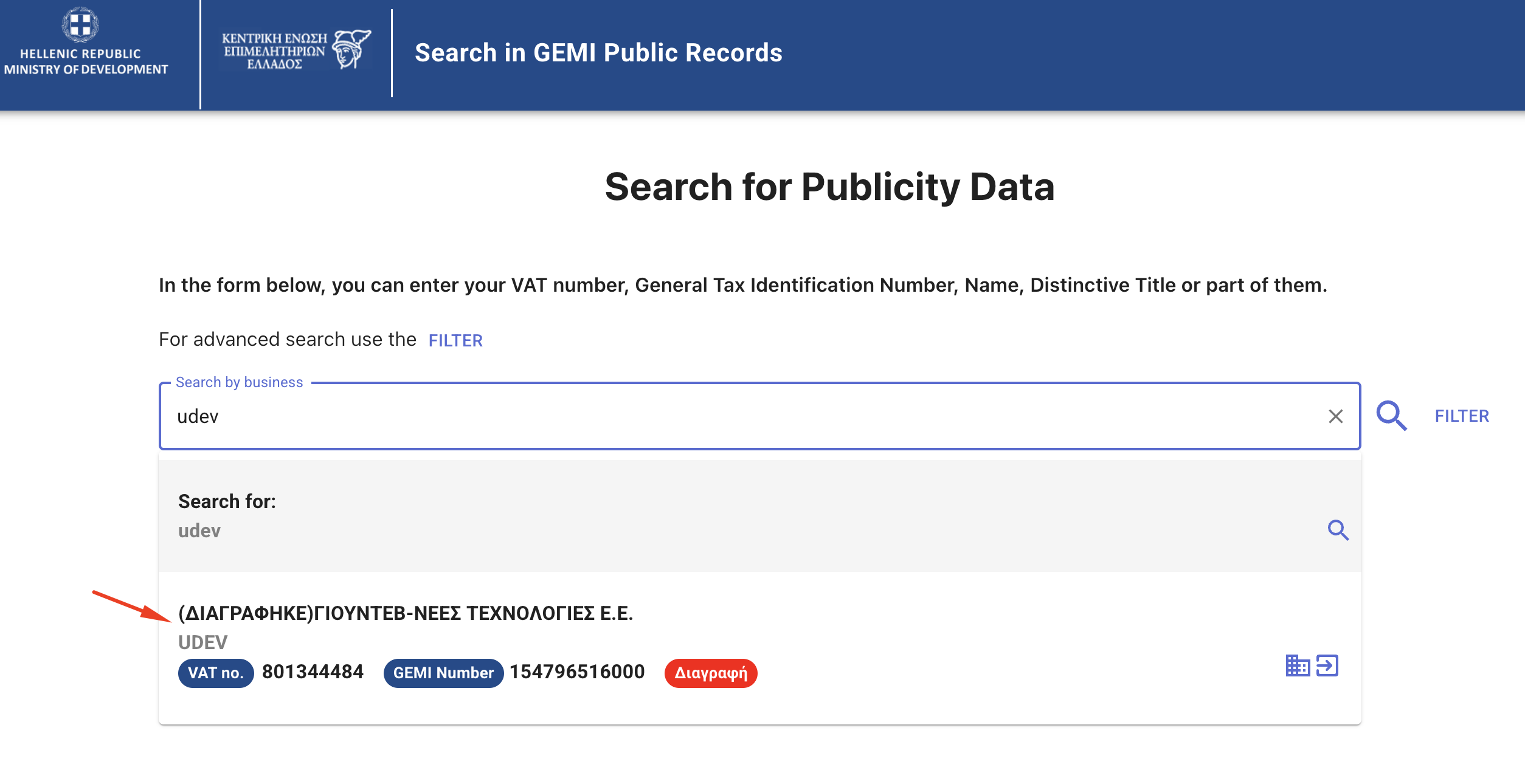
2. Enter 'udev' in the search bar and select the company
[image: image.png]
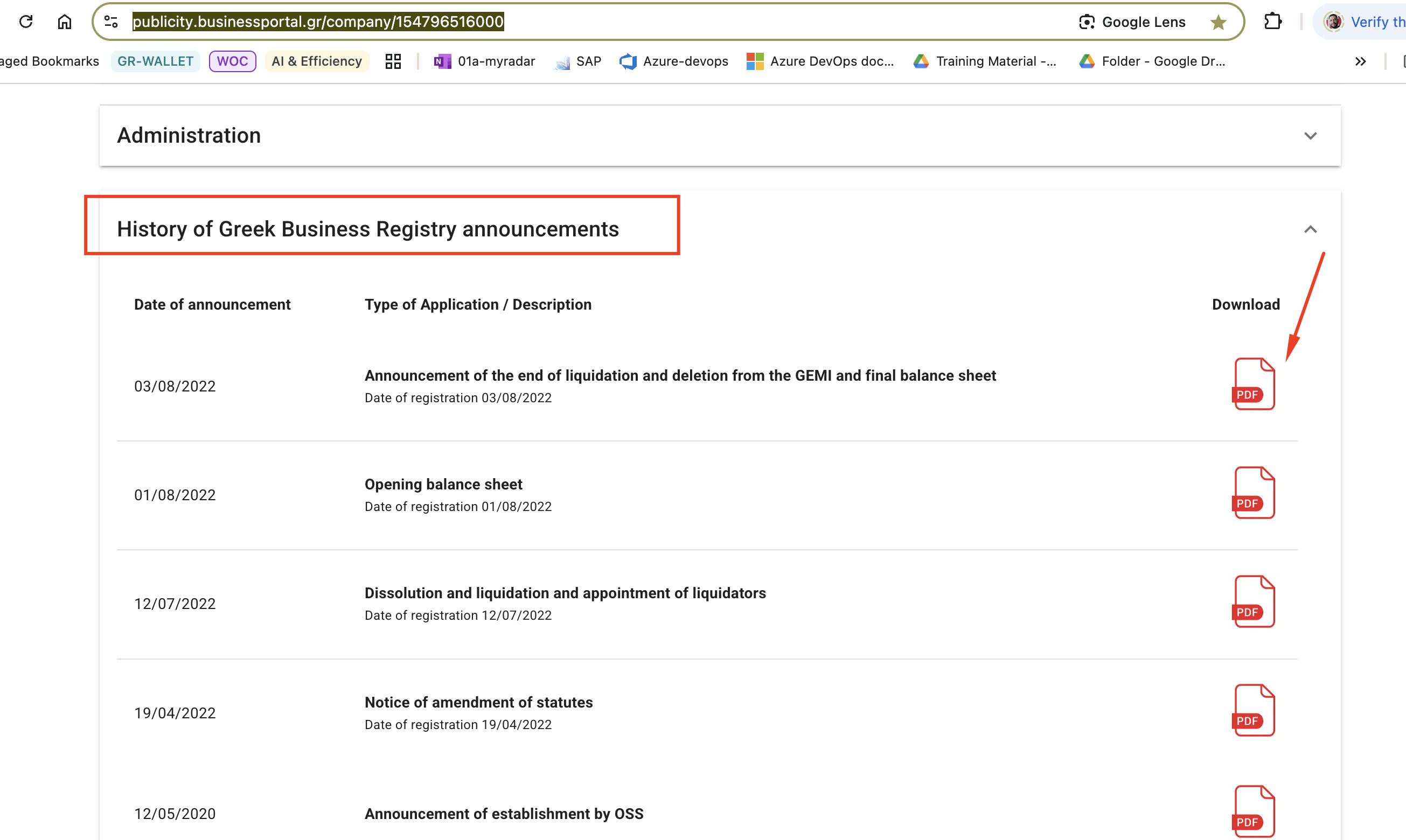
3. Select "History of Greek Business Registry announcements" ("Ιστορικό
ανακοινώσεων Γ.Ε.ΜΗ." in Greek) to find related PDFs
[image: image.png]
4. Download the PDF 'Announcement of establishment by OSS'
[image: image.png]
The goal is to be able to parse specific data from PDFs (expecting various
templates to be used by the lawyers of each company) and extract
information for legal representatives, eg. I was representing UDEV, and
this info can be found under section 6
[image: image.png]
So the challenge here is the language, various doc templates, the specific
info we want to extract from files which probably have been exported to
PDFs in various ways, and on top of that to keep version history of the
extracted data.
Regards,
Giannis
--
Ioannis Skitsas
On Thu, Apr 3, 2025 at 6:39 PM iordanis sapidis <iordanis231 [ at ] hotmail [ dot ] com>
wrote:
> Hello GFOSS,
>
> My name is Iordanis and I am a master's student in the University of Crete
> studying computer science. Ι am interested in participating with the
> project Flexible GovDoc Scanner, but I am unsure what specific information
> we aim to extract from the PDF documents that is not already available
> through the API (https://opendata.businessportal.gr/).
>
> For example, details such as board members and incorporation
> history appear to be accessible through the API.
>
> Do the PDF documents contain additional information?
>
> Furthermore, where can I find the PDF documents mentioned in the project
> description? When I search through Greece's business portal (
> https://publicity.businessportal.gr/), I only see company information
> displayed directly on the webpage in a structured format, but I don’t see
> any downloadable PDFs.
>
>
> Sincerely,
>
> Iordanis Sapidis
>
> ----
> Λαμβάνετε αυτό το μήνυμα απο την λίστα: Λίστα αλληλογραφίας και συζητήσεων
> που απευθύνεται σε φοιτητές developers \& mentors έργων του Google Summer
> of Code - A discussion list for student developers and mentors of Google
> Summer of Code projects.,
> https://lists.ellak.gr/gsoc-developers/listinfo.html
> Μπορείτε να απεγγραφείτε από τη λίστα στέλνοντας κενό μήνυμα ηλ.
> ταχυδρομείου στη διεύθυνση <gsoc-developers+unsubscribe [ at ] ellak [ dot ] gr>.
>


----
Λαμβάνετε αυτό το μήνυμα απο την λίστα: Λίστα αλληλογραφίας και συζητήσεων που απευθύνεται σε φοιτητές developers \& mentors έργων του Google Summer of Code - A discussion list for student developers and mentors of Google Summer of Code projects.,
https://lists.ellak.gr/gsoc-developers/listinfo.html
Μπορείτε να απεγγραφείτε από τη λίστα στέλνοντας κενό μήνυμα ηλ. ταχυδρομείου στη διεύθυνση <gsoc-developers+unsubscribe [ at ] ellak [ dot ] gr>.